By 2030, artificial intelligence (AI) will save the banking industry more than $1trn, according to analysts. Of that vast sum, it is expected that banks and credit unions will save $217bn—simply by applying AI to their compliance and authentication practices, and to other forms of data processing.
In a past article, I reviewed the first steps that financial institutions can take to transform their AML compliance and fraud prevention programs, augmenting their rules-based systems with AI-driven models. This includes implementing advanced anomaly-detection models and transaction monitoring, with machine learning and robotic process automation (RPA).
AI for AML Compliance
Adding AI to your program is not a process where you simply hire a vendor to “program” an AI system to detect threats within your organization. It is instead a multi-step and collaborative process where the experts within a financial institution work closely with data scientists to train the AI system to determine whether seemingly abnormal behaviors or clusters of transactions are suspicious or fraudulent.
There also isn’t one model that works for all organizations, which can make the implementation and training process take more time than might be expected. But once you’ve finished your training, you’ll be closer to having a solution that integrates your data and meets your AML and fraud detection and prevention needs.

Figure 1: Steps to get started on adding AI-based capabilities to an AML or fraud detection program
Exploratory Analysis
To begin developing an AI-driven AML or fraud detection program, users first perform an exploratory analysis to examine supporting data and reveal existing patterns.
After identifying potential patterns, our data scientists guide our clients to help them understand and interpret exactly what they are seeing. This is done through a series of questions such as, “Are these supposed to be here?” and “Are these graphs supposed to be this steep?” The answers to these questions will then guide the next phase of the program.
Data Cleansing
With answers to these questions, we can then cleanse the data in a twofold process.
In our first step, we work with our clients on any data issues, such as completing fields without values or converting text fields into a numerical format, or another format that is useable by the machine-learning models.
Step two is much more involved. Called “feature engineering”, this is where, with your teaching, the machine begins to understand the data. Patterns and information revealed in data may be obvious to us, but a machine that is looking at numbers might struggle without any context.
Let us consider date stamps. Humans quickly understand and question the difference between times and dates, but machines don’t. They must be programmed to ask, “Why are these transactions three seconds apart and those transactions two days apart?” To solve this particular problem we engineer an extra column of data for “time between transactions” that is easily ingested and understood by a machine.
Create a Ground Truth
After preparing the data, the next step is building the “ground truth”. This is where we create a baseline, or the model that establishes what is expected, or normal, behavior.
To create the ground truth, the system takes in all the supporting data and starts grouping them by characteristics that were developed in the feature engineering stage. Any anomalies are isolated for review – are they “normal” or are they “suspicious or fraudulent”?
Apply Various Machine Learning Models
Once the ground truth has been created, the next step is applying the various machine learning models. Very rarely do you have one model doing everything.
There are typically two approaches:
Leverage several models and take the average score
Take a linear approach where one model teaches another model, which teaches another model, and so on.
In either case, the intent is to create a set of results that are likely to be suspicious or fraudulent.
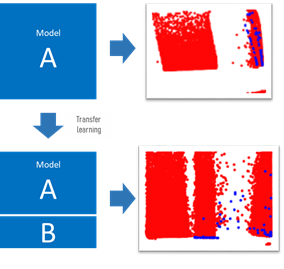
Figure 2: A linear approach where one model teaches another model, which teaches another model and so on, is one way to build the ground truth.
The last step in the process is results analysis. It is amazing how the system can take different data sets and convert them into a human-friendly form that can be validated by people.
Once the results have been validated, the process is complete and the system is ready for full-scale deployment.
Continuous Training of AI-Models
Once a model has been created, it does not change until you retrain it. In that way, it is not different from humans. If a new product is introduced into the company, you have to train your staff on how to sell and support it.
AI models work in the same way. As data and transactions change, the model updates along with these changes. Without this training, you have data degradation.
When retraining the model, you do not scrap what you already have developed. It is like when you are learning grade 12 math – you do not scrap what you learned from kindergarten to grade 11. Instead, that previous knowledge acts as a foundation for the new things that you are learning.
Data Quality and Scoring
It is important to note when you are building the ground truth and training the model that feeding the model vast amounts of fraudulent transactions will normalize fraudulent behavior in the model. Therefore, it is important during the training stage that clean data is labeled advantage (i.e. training data) and suspicious activities are labeled tagged.
Once the ground truth is established, the system will accept future data and provide a score of how it compares to a “normal” transaction.
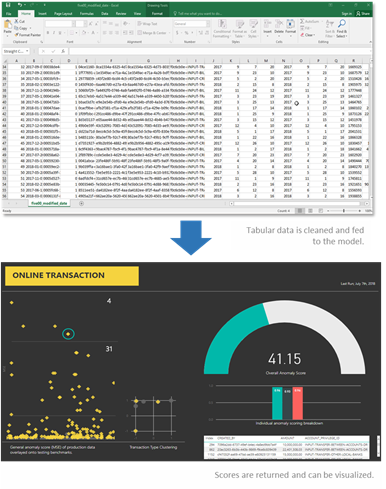
Figure 3: Tabular data is fed into the models to create the ground truth and future transactions are scored against this baseline.
Supervised Versus Unsupervised Learning
These two terms are often used when talking about incorporating machine learning into an AML program, so what do these terms mean?
In supervised learning, you know exactly what you’re looking for. This analytic approach uses historical data to predict suspicious behavior similar to past patterns. For example, an organization might say that multiple transactions in rapid succession on the same day and from different locations should be flagged as potential credit card fraud while large ATM cash deposits should be flagged as potential money laundering.
Unsupervised learning occurs when you do not tell the algorithm what to look for. This analytic approach examines current behavior to identify abnormal transactions or patterns that warrant closer investigation. Unsupervised learning, which includes anomaly detection, is a powerful tool because it allows financial institutions to discover new fraud and money laundering schemes. They can also strengthen their compliance and fraud prevention programs, without inherited bias towards patterns found in supervised models.
Once the model has been trained, “transfer learning” can be applied. This is where new data sets are applied to existing AI models. In the case of the banking sector, models that are built for retail banking could be applied to trade transactions to generate new insights.
Setting Realistic Expectations
Committing to growing an AML or fraud detection program with AI and machine learning is a big commitment. Businesses need to set realistic expectations of what the technology can and cannot do.
While many financial institutions have opted to create their own data science teams to tackle these projects, there are some drawbacks to this approach. There is currently a shortage of data science engineers, and finding the right staff can be a challenge. Extracting and cleansing the data from the various data infrastructure systems requires a different set of skills than those involved in machine learning.
For this reason, many institutions work with external solution providers to help them get started with their programs. Companies like us have experience with data extraction, data management, cross-functional/department data analysis, and of course, AI and machine learning. Experience with implementing models for other organizations also reduces the time it takes to get started with an AI-driven program.
Once a financial institution has successfully implemented an AI-driven solution they can start seeing benefits including lower operating costs due to process automation, better compliance, fraud detection, increased productivity, and effortless customer experience.
To learn more about the benefits of AI for AML and how software can help streamline your compliance program, contact us today.



